The human visual perception system demonstrates exceptional capabilities in learning
without explicit supervision and understanding the part-to-whole composition of objects.
Drawing inspiration from these two abilities,
we propose Hierarchical Adaptive Self-Supervised Object Detection (HASSOD),
a novel approach that learns to detect objects
and understand their compositions without human supervision.
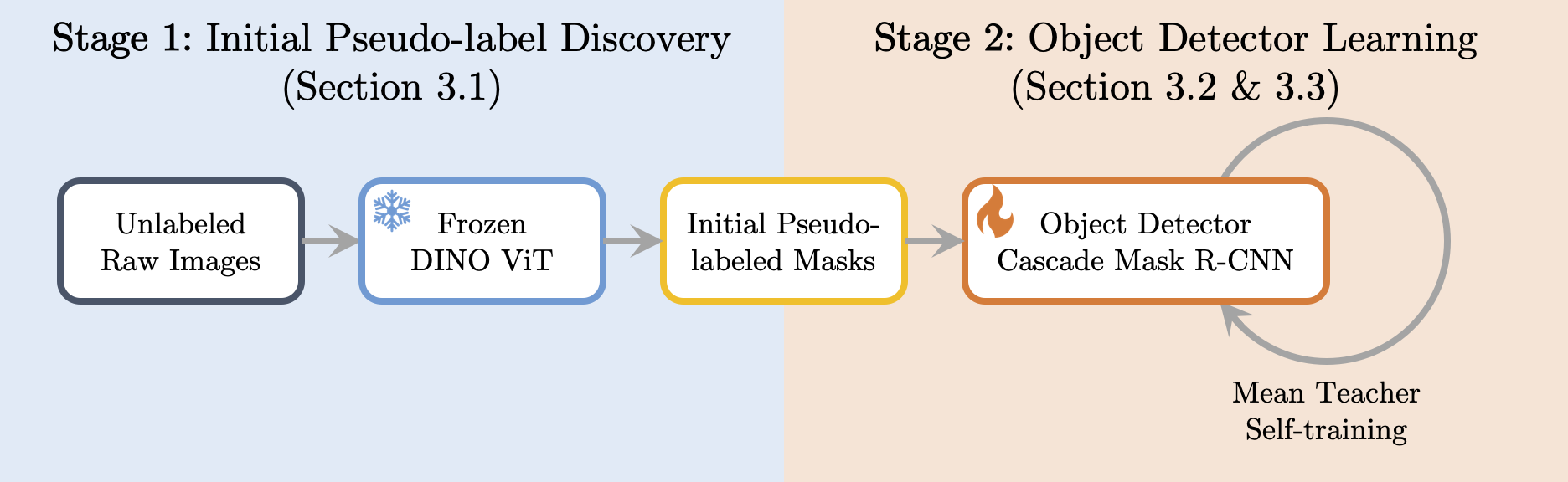
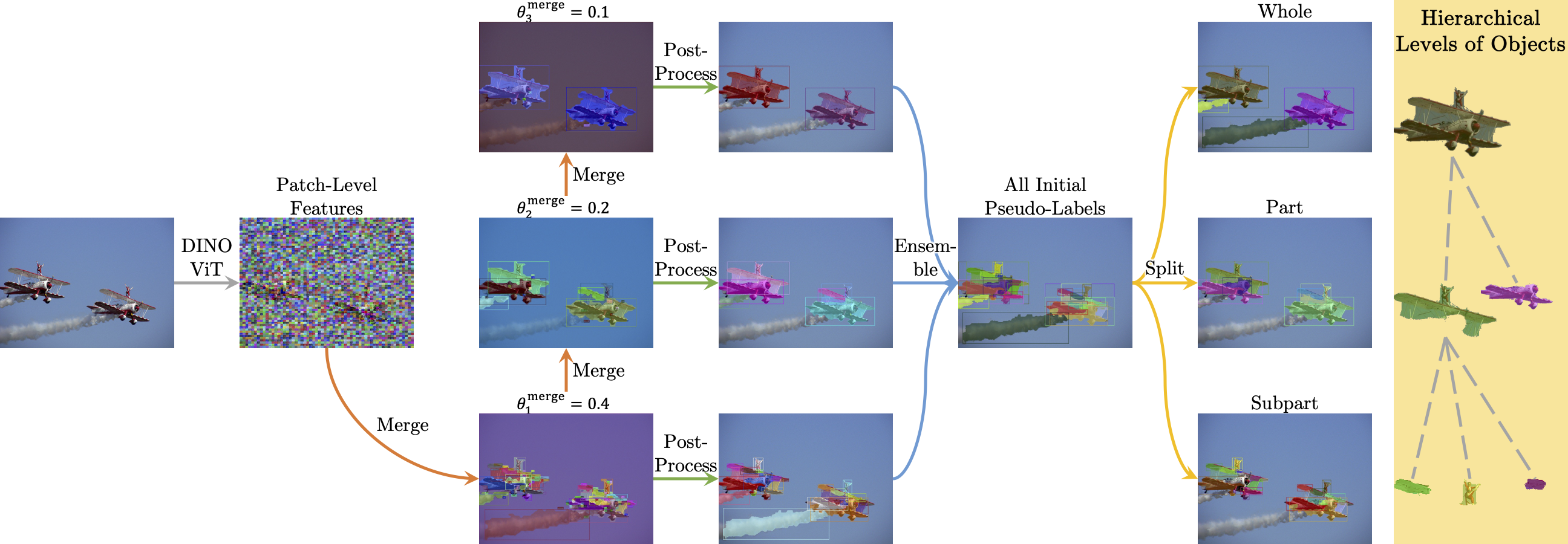
HASSOD employs a hierarchical adaptive clustering strategy
to group regions into object masks based on self-supervised visual representations,
adaptively determining the number of objects per image.
Furthermore, HASSOD identifies the hierarchical levels of objects in terms of composition,
by analyzing coverage relations between masks and constructing tree structures.
This additional self-supervised learning task leads to
improved detection performance and enhanced interpretability.
Lastly, we abandon the inefficient multi-round self-training process utilized in prior methods
and instead adapt the Mean Teacher framework from semi-supervised learning,
which leads to a smoother and more efficient training process.
Through extensive experiments on prevalent image datasets,
we demonstrate the superiority of HASSOD over existing methods,
thereby advancing the state of the art in self-supervised object detection.
Notably, we improve Mask AR from 20.2 to 22.5 on LVIS, and from 17.0 to 26.0 on SA-1B.